Chip S2
BitElectrum Corp
The S2 chip from BitElectrum Corp. can be used for various applications, including artificial intelligence (AI).
This chip provides computational resources that can be utilized for data processing, running machine learning algorithms, and other tasks related to artificial intelligence. Its low power consumption and high performance make it an attractive choice for tasks that require significant computational power, such as neural network training and large-scale data analysis.
The continuous advancement of AI/ML technologies, which involve the utilization of highly intricate algorithms for processing vast datasets, has driven the evolution of novel architectures. These architectures are engineered to address a diverse spectrum of tasks while simultaneously delivering superior performance and reduced power consumption. Additionally, they hold great potential in tackling the ambitious goal of achieving "Strong AI."
Strong AI, also known as Artificial General Intelligence (AGI), refers to the theoretical intelligence of a machine that possesses the capability to comprehend and learn any intellectual task to the extent that a human can. This notion, famously explored by figures like Ray Kurzweil in his work "The Singularity Is Near" (2005), envisions machines with human-like cognitive abilities.
Multicell Platform Base: Architecture
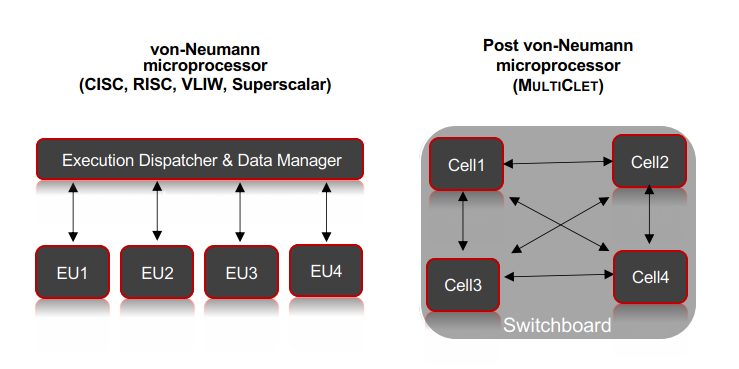
The BitElectrum Corp. has pioneered a groundbreaking microprocessor architecture designed to harness the power of teamwork. The outcome is a multicellular microprocessor featuring a decentralized system of autonomous execution units known as "cells." These cells operate concurrently, employing a broadcast mechanism that ensures results are shared comprehensively, adhering to the principle of "all, from all, to all." This innovative approach redefines how microprocessors function, unlocking new possibilities for efficient and collaborative processing.
Main Features of Multicellular Architecture
- Queuing and Processing Blocks: A multicellular processor is designed as a queuing and processing system, comprising blocks that handle incoming requests.
- Dynamic Reconfiguration: The architecture allows for dynamic reconfiguration or redistribution of processor cores among concurrently executing tasks without interrupting the computational process.
- No Global Pipeline: Unlike some architectures, there is no global pipeline in a multicellular processor.
- Parallel Processing: A four-cell processor can concurrently process up to 64 commands, with each command potentially being at any stage of execution.
- Unidirectional and Fully Connected Switch Board: The switch board (SB) in this architecture is unidirectional and fully connected, facilitating efficient communication.
- Shared Results: All results generated by commands executed in different cells are accessible to all cells simultaneously due to the direct interconnection of cells.
- No Need for Branch Predictions: This architecture eliminates the need for branch predictions and speculative execution, potentially simplifying processor design and improving efficiency.
- Straight Implementation of SSA: The instruction set is a direct implementation of Static Single Assignment (SSA), which is an intermediate compiler language often used in optimizing compilers like LLVM.
These features collectively enable efficient and dynamic processing of tasks in a multicellular architecture, making it suitable for a wide range of computing applications.
Multicellular Platform Components
Core configuration options - homogeneous, heterogeneous, matrix.
- Cell Units: The fundamental building blocks of the multicellular platform are the cell units. These autonomous processing entities handle specific tasks simultaneously and efficiently.
- Dynamic Reconfiguration Module: This module allows for the reallocation and redistribution of tasks among the cell units without interrupting ongoing computations. It ensures optimal resource utilization.
- Switch Board (SB): The unidirectional and fully connected switch board facilitates communication and data exchange among the cell units.
- Global Command Processing: The multicellular platform can process up to 64 commands simultaneously, with each command capable of being at any stage of execution. This allows for high-throughput processing.
- Direct Result Sharing: Thanks to the direct connections between cell units, the results of all commands are readily available to every part of the system simultaneously, eliminating the need for complex data routing.
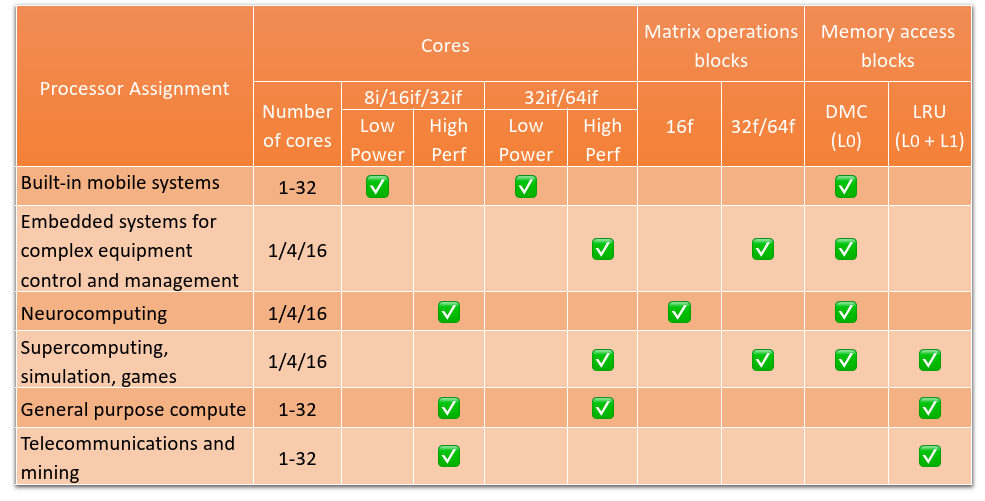
Target market segments of the Multicellular Platform
Performance on Mining Applications
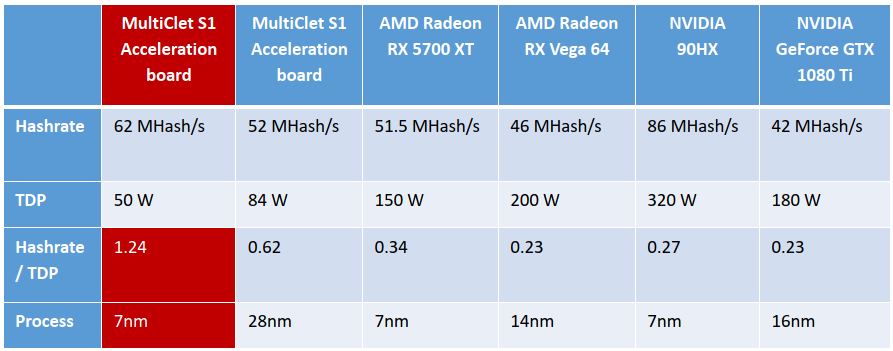
In the context of Ethereum mining applications, BitElectrum's Acceleration board, which is powered by 16 Electrum Chip S1 processors, demonstrates remarkable efficiency. Even when using 28nm technology, it outperforms the latest NVIDIA 90HX mining board by more than double in terms of efficiency. Looking ahead to 7nm technology, estimates suggest an impressive 1.24 Hashrate / TDP (Hashrate per Total Dissipated Power) ratio. This level of efficiency positions BitElectrum's mining solutions as a compelling choice for Ethereum miners seeking both performance and energy efficiency.
С Compiler Benchmarks
Example of how the Multicell C compiler LLVM works on a poorly parallelized task, used CoreMark/Mhz ratio
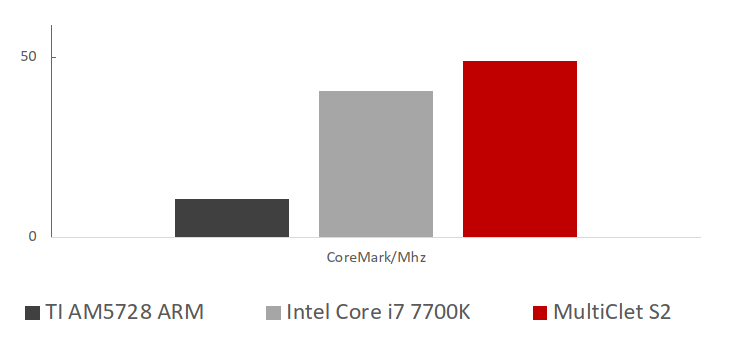
Here's an example of how the BitElectrum C compiler, which utilizes LLVM, operates on a task that is poorly parallelized, using the CoreMark/MHz ratio as a benchmark:
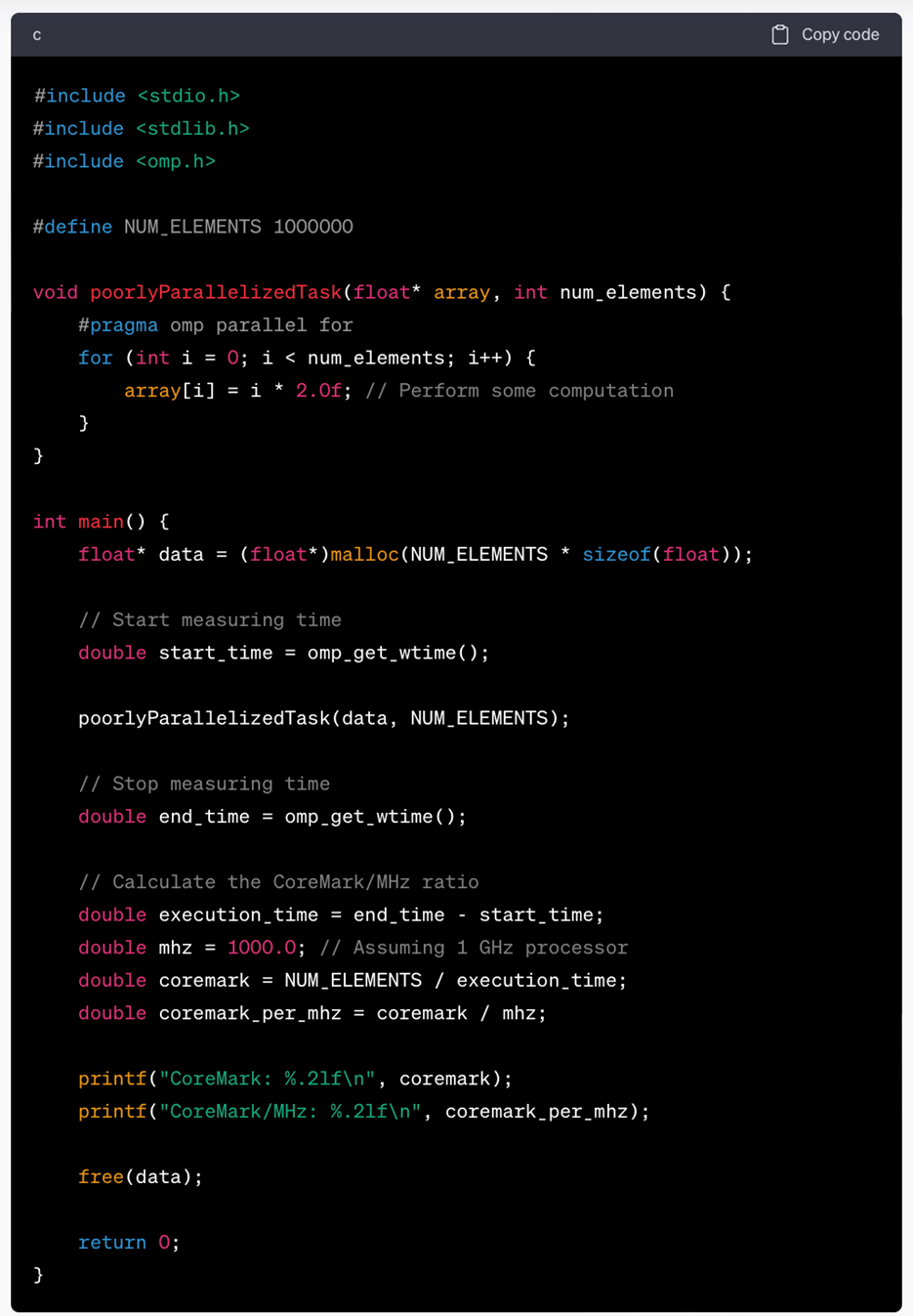
In this example:
- We have a poorly parallelized task represented by the function poorlyParallelizedTask, which performs a simple computation on an array of floating-point numbers.
- OpenMP directives (#pragma omp parallel for) are used to parallelize the loop, but the task itself is not well-suited for parallelization.
- We measure the execution time of this task using omp_get_wtime() to calculate how long it takes to complete.
- We assume a 1 GHz processor for simplicity and calculate the CoreMark/MHz ratio, which gives us an idea of the computational efficiency of this poorly parallelized task on a given processor.
This example demonstrates how the BitElectrum C compiler, utilizing LLVM, can be used to analyze the performance of tasks, even those that are not optimized for parallel execution, using the CoreMark/MHz ratio as a metric.
ECAD Comparison of Multicell S2
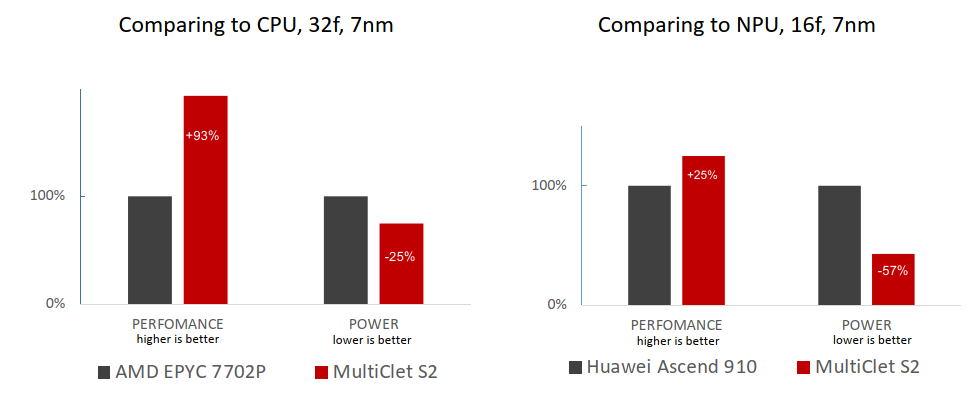
Cycle Based Performance on Tests
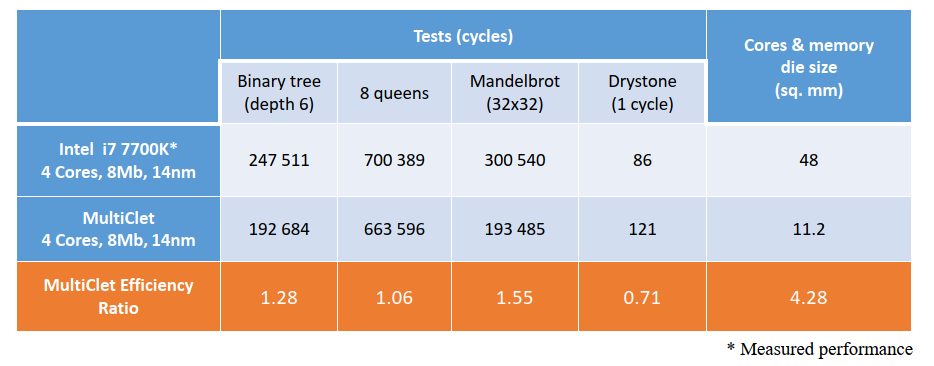
- Cycle based performance of a quad-core multicellular processor exceeds the performance of both a quad-core Intel i7 7700K
- Extremely efficient use of hardware resources - the number of simultaneously selected and decoded commands in a multicellular processor is 1.5-2 times less at full load compared to the competitors
- Die area allocation is more than 4 times smaller compared to the competitors
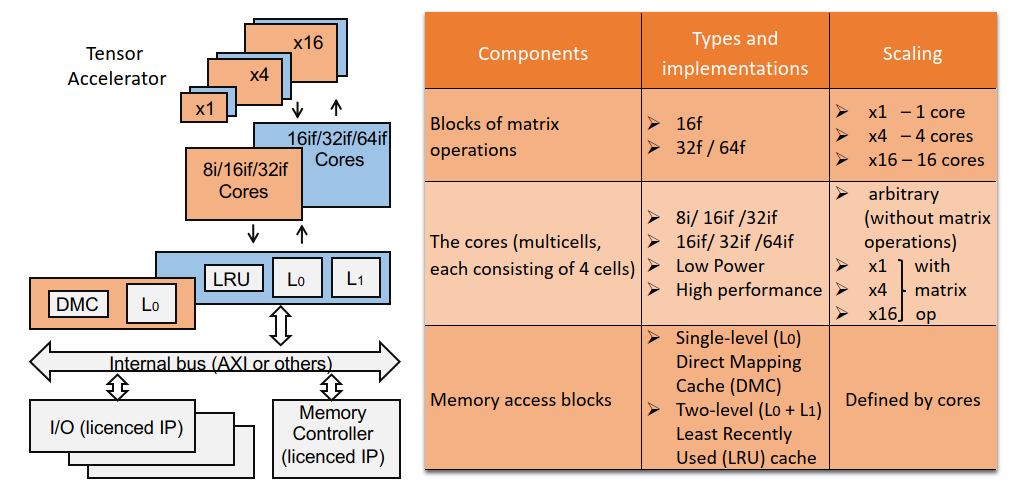
FPGA: Electrum Chip multicellular core features
- Natural parallelism with direct implementation of SSA (LLVM).
- The core consists of four cells (with the possibility of scaling up).
- Each core can simultaneously fetch and decode up to four instructions.
- Instruction formats are available in 32/64/96 bits.
- Data formats include 16/32/64 bits.
- Supported instruction set architecture (ISA) includes integer (16/32/64) and float (32/64) operations.
- Cache architecture follows a direct-mapped cache (DMC) approach.
- The cache size can be selected during the synthesis stage.
- Gate count for the ASIC core is 4.2 million, and 1.7 million without memory.
- Gate count for FPGA implementation is 58,000 LUTs (core and cache).
Possible AI/ML configurations for FPGA platforms
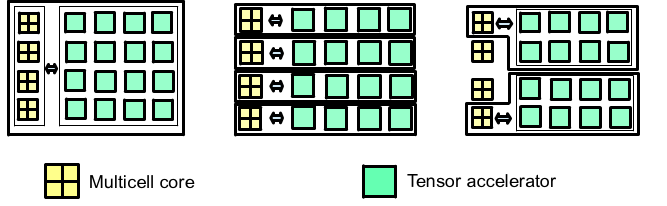
Homogeneous:
- A quad-core processor accompanied by a tensor accelerator block for handling big data and high-performance applications
- Four processors integrated with tensor accelerators, suitable for tackling a substantial volume of loosely coupled problems of the same type.
- A configuration consisting of two processors with tensor accelerator blocks and two scalar processors, optimized for handling both computational tasks and management functions.